
Overview
CLLT specializes in developing computational resources and tools for Modern Greek and its dialectal varieties. Our work addresses the critical gap in NLP resources for Greek, which remains significantly under-resourced compared to major European languages.
We focus on creating high-quality datasets, benchmarks, and models that capture the linguistic variety of Greek, including its standard form and dialects.
Greek Dialects Dataset (GRDD)
GRDD & GRDD+
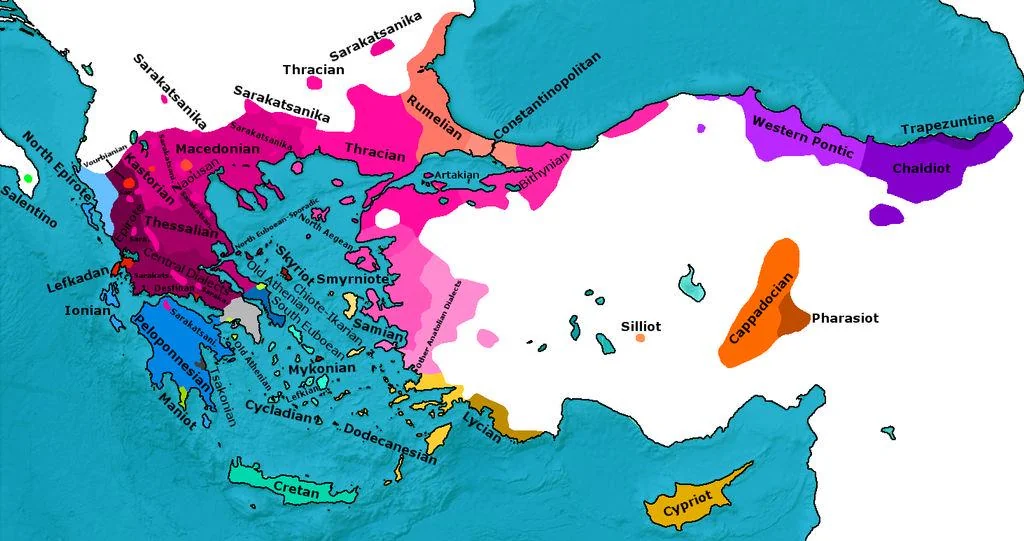
The Greek Dialects Dataset (GRDD) is a comprehensive corpus covering four major dialectal varieties of Greek: Cypriot, Pontic, Cretan, and Northern Greek. This resource enables NLP research on low-resource language varieties.
Key Features:
- Multi-dialectal coverage
- Fine-tuning experiments across multiple model architectures
- Publicly available for research
Dialectal Llama-krikri
Specialized for Cypriot, Cretan, Pontic and Northern Varieties

Cretan Dialect
Fine-tuned model for Cretan Greek

Cypriot Dialect
Specialized model for Cypriot Greek

Northern Greek Dialect
Model trained on Northern Greek varieties

Pontic Dialect
Model for Pontic Greek
Explore the source code and download the trained adapters:
OYXOY Benchmark
OYXOY is a modern NLP test suite for Modern Greek, featuring expert-verified evaluation tasks for natural language inference, word sense disambiguation, and metaphor detection.
Innovation: First finer-grained and multi-label NLI dataset for Greek, and the first dataset to use a traditional resource to automatically extract information and construct polysemy and metaphor datasets.